
By Tao Sauvage
TL;DR: I reversed the firmware of my Garmin Forerunner 245 Music back in 2022 and found a dozen or so vulnerabilities in their support for Connect IQ applications. They can be exploited to bypass permissions and compromise the watch. I have published various scripts and proof-of-concept apps to a GitHub repository. Coordinating disclosure with Garmin, some of the vulnerabilities have been around since 2015 and affect over a hundred models, including fitness watches, outdoor handhelds, and GPS for bikes.
Check out my presentation at HITBSecConf2023 about it here.
Why Garmin’s Sport Watches?
Garmin is a key player in the global market for fitness devices. In 2020, it was 2nd, behind Apple, in the global smartwatch market according to Counterpoint Research. In terms of the security of their devices, I did not find much information online. I was therefore interested to dig further since this uncharted territory could affect a substantial number of end-users, myself included.
In early 2022, the only information I could find online was the following interesting blog post from Atredis: "A Watch, A Virtual Machine, and Broken Abstractions" by Dionysus Blazakis (2020). It provided an insight into how the Garmin Forerunner 235 worked and how their applications, named Connect IQ (CIQ) applications, were implemented. Blazakis’ blog post kickstarted my whole journey and I am building on top of their research.
Vulnerabilities
As a teaser, below is the list of vulnerabilities that I found during my project and disclosed to Garmin:
| Anvil ID | CVE ID |
CIQ API
Version (minimum) |
Summary |
| GRMN-01 |
No CVE requested
|
1.0.0 |
TVM does not ensure that
toString returns a String object |
| GRMN-02 | CVE-2023-23301 | 1.0.0 |
Out-of-bound read when loading string resources
|
| GRMN-03 |
No CVE requested
|
1.0.0 |
Inconsistent size when loading string resources
|
| GRMN-04 | CVE-2023-23298 | 2.3.0 |
Integer overflows in
BufferedBitmap initialization |
| GRMN-05 | CVE-2023-23304 | 2.3.0 |
SensorHistory permission bypass |
| GRMN-06 | CVE-2023-23305 | 1.0.0 |
Buffer overflows when loading font resources
|
| GRMN-07 | CVE-2023-23302 | 1.2.0 |
Buffer overflows in
Toybox.GenericChannel.setDeviceConfig
|
| GRMN-08 | CVE-2023-23303 | 3.2.0 |
Buffer overflows in
Toybox.Ant.GenericChannel.enableEncryption
|
| GRMN-09 | CVE-2023-23306 | 2.2.0 |
Relative out-of-bound write in
Toybox.Ant.BurstPayload
|
| GRMN-10 | CVE-2023-23300 | 3.0.0 |
Buffer overflows in
Toybox.Cryptography.Cipher.initialize
|
| GRMN-11 |
Same as GRMN-09
|
2.2.0 |
Type confusion in
Toybox.Ant.BurstPayload
|
| GRMN-12 |
No CVE requested
|
1.0.0 |
Native functions do not check the number of arguments
|
| GRMN-13 | CVE-2023-23299 | 1.0.0 |
Permission bypass via field definition manipulation
|
We coordinated disclosure with Garmin through 2022 and 2023 (see the Responsible Disclosure Timeline section). They clarified that several of the vulnerabilities were there since version 1.0.0, published in January 2015.
They also clarified that the vulnerabilities affected over a hundred devices, based on the list of Connect IQ Compatible Devices and fixed in CIQ API version 3.1.x as specified by Garmin.
Pre-Research
The CIQ applications are executed inside a virtual machine (named TVM in the firmware, which I read as "The Virtual Machine") implemented in their Garmin Operating System (aptly named GarminOS). TVM is mainly used for stability but it also adds a security layer:
- If the application takes too long to execute, the VM aborts it.
- The VM takes care of allocating and freeing memory, to prevent memory leaks.
- The VM stops applications from accessing sensitive APIs if they do not have the correct permissions (e.g. accessing GPS location).
Atredis' blog post focused on the security of TVM's operation codes (opcodes) that are implemented natively. It highlighted several critical issues that can be exploited with malicious assembly code to break the virtualization layer and gain native code execution on the watch, allowing full control.
The attack scenario is for a user to install a malicious CIQ application (manually or from the Connect IQ Store). We can make the parallel with Android applications, where a user installs a malicious APK on their mobile device, either from the Play Store or by side-loading it.
I recommend giving Atredis' blog post a read if you're interested. Although they only list the Forerunner 235 model in their advisory, I strongly suspect that the vulnerabilities they found affected a much wider range of devices.
In my journey, I was interested in analyzing three additional aspects of Garmin applications that could represent potential attack vectors:
- How does GarminOS load CIQ apps?
- What are the native functions briefly mentioned in Atredis' blog post?
- How are app permissions implemented?
GarminOS and TVM
GarminOS is a fully custom OS developed in-house by Garmin, which, to say the least, is not common nowadays. It implements threading and memory management but does not have a concept of user-mode vs. kernel mode, nor does it support multiple processes for instance. It is mostly written in C, with the UI framework starting to move to C++ over the past couple of years (based on this podcast linked in this random Garmin forum message I found through shear luck).
Public documentation of their OS is limited but we know that their watches use ARM Cortex M series processors, which can help with reverse-engineering later. Here, we will be analyzing and testing the Garmin Forerunner 245 Music model.
Interestingly, Garmin developed their own programing language named MonkeyC, which is used to write applications that can run on the watch. They provide an SDK and API documentation that developers can rely on to develop CIQ applications.
The MonkeyC language is a mix between Java and JavaScript, among others. It compiles into byte code that is interpreted by Garmin's TVM.
Here is an example of a simple MonkeyC program that outputs "Hello Monkey C!" to the log file of the app:
import Toybox.Application as App;
import Toybox.System;
class MyProjectApp extends App.AppBase {
function onStart(state) {
System.println("Hello Monkey C!");
}
}
Firmware Analysis
I initially tried analyzing the firmware update that is temporarily stored on the watch when it prompts you to update. However, I quickly realized that this was an incremental build and did not contain the whole firmware.
Fortunately, Garmin provides beta firmware images on their website, which contain everything. They are structured as GCD files, a file format that was unofficially documented by Herbert Oppmann.
Parsing the GCD firmware update, I extracted the FW_ALL_BIN record that contained the raw image for my watch:
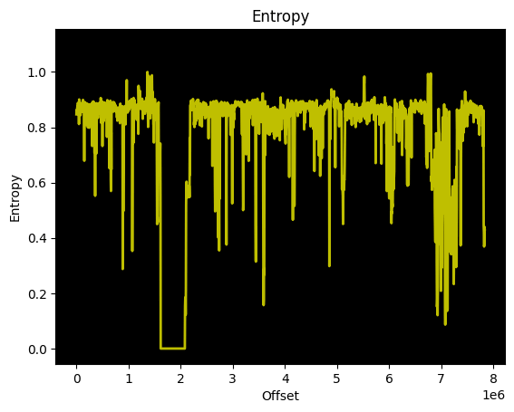
I could then directly load the firmware image as ARM:LE:32:Cortex using Ghidra, with the following memory map after some trial and errors:

You will note the starting address at 0x3000 for the flash. I mentioned that the beta firmware images contained everything but it is not accurate, since they are missing the bootloader that is most likely located between address 0x0 and 0x3000.
Various miscellaneous information I gathered during reverse-engineering:
- MonkeyC has 21 data types:
// MonkeyC data types NULL(0), INT(1), FLOAT(2), STRING(3), OBJECT(4), ARRAY(5), METHOD(6), CLASSDEF(7), SYMBOL(8), BOOLEAN(9), MODULEDEF(10), HASH(11), RESOURCE(12), PRIMITIVE_OBJECT(13), LONG(14), DOUBLE(15), WEAK_POINTER(16), PRIMITIVE_MODULE(17), SYSTEM_POINTER(18), CHAR(19), BYTE_ARRAY(20);
- TVM converts those objects into a 5-byte structure that is pushed onto the stack:
- The first byte represents the data type (
0x01forint,0x02for float,0x05forArray,0x09for Boolean, etc.) - The 4 remaining bytes represent either the direct value (e.g.
0x11223344for an integer encoded using 32 bits) or an ID pointing to another structure located on the heap for more complex types (Hash,Array,Resource, etc.)
- The first byte represents the data type (
- TVM supports a total of 53 opcodes (full list here)
- Including common ones like
add,sub,return,nopfor instance. - As well as more specialized ones like
newba(to allocate ByteArray objects) orgetm(to resolve modules when using theimportorusingstatement) for example. - Those opcodes are implemented in native code in C and were the focus of Atredis' research, as mentioned before.
- Including common ones like
CIQ Applications
When compiling a CIQ application, the SDK generates a PRG file (I read it as "Program”) containing multiple sections including the code, data, signature and permissions sections, to name a few.
PRG sections are defined using Type-Length-Value (TLV) encoding, with:
- 4 bytes: the section type, using a magic value (e.g. 0xc0debabe for the code section)
- 4 bytes: the section length
- n bytes: the section data, as specified in the section length
I very much enjoy Kaitai Struct when I need to analyze binary blobs interactively. I wrote a Kaitai structure for PRG files, with support for disassembling (but not for resources; I think my Kaitai skills are not good enough for that). It is available on our GitHub.
For example, disassembling the TLV sections can be done as follows:
section:
doc: A section
seq:
- id: section_type
type: u4
- id: length
type: u4
- id: data
size: length
type:
switch-on: section_type
cases:
# [...]
section_magic::section_magic_head: section_head
# [...]
enums:
section_magic:
# [...]
0xd000d000: section_magic_head
# [...]
Signature
The PRG files are signed using RSA and the PKCS #1 v1.5 standard with SHA1. They can hold either of the following signature sections:
- App Store signature
- Developer signature
In the first case, only the 512-byte signature is included. In the second case, both the 512-byte signature and the public key is included. There does not seem to be an option to reject developer-signed apps on the watch.
It is straightforward to add support for developer signature in our Kaitai structure:
section_developer_signature_block:
doc: Developer signature block
seq:
- id: signature
size: 512
- id: modulus
size: 512
- id: exponent
type: u4
When the compiler creates a PRG file, it first generates and appends all the sections (head, entry points, data, code, resource, and so on). It then computes the RSA signature and appends the signature section. Finally, it appends the end section, which contains all zeros (magic value is 0, and length is 0, for a total of 8 bytes).
I only performed a cursory review of the signature validation process, only just enough so that I could sign my own patched PRG files.
If anyone is interested in looking closer at the signature validation performed by the firmware, let me know. I would love to team up. You can find my contact details at the bottom of this post.
Attack Surface
Since parsing PRG files is performed in native code, it is an interesting attack surface:
- The file format contains multiple offsets that could lead to integer over/underflows if they are not properly validated.
- It specifies the permissions the application needs, as well as the signature for validation.
- It contains a link table and other information used for resolving symbols or handling exceptions during execution.
- It is possible to embed complex data structures within the PRG file, including images, animations and fonts, among others.
Fortunately, Garmin properly handles section lengths (as far as I could tell). Other length attributes within those sections are often encoded using 2 bytes but stored inside 4-byte integers in the code, preventing a lot of integer overflow scenarios.
But there are still many elements to check. Let's go over several issues that I found while reversing PRG loading.
Resources
MonkeyC supports several types of resources. Their documentation mentions strings, bitmaps, fonts, JSON data and animations.
String Definitions
String definitions (as shown below) are processed by the news opcode. When calling news, you pass the symbol to your string definition, which usually points inside your PRG's data section. A string definition starts with the sentinel value 0x1, followed by the string length encoded using 2 bytes, followed by the string bytes.
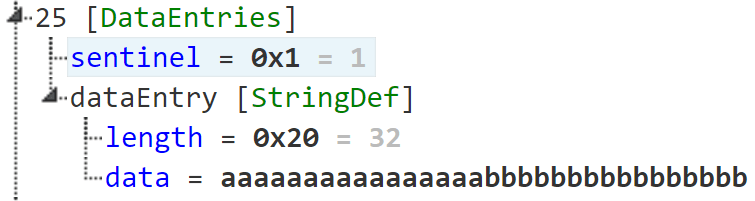
The Atredis' CVE-2020-27486 advisory explains that the news opcode allocates the string buffer based on the length specified in the string definition, and then proceeds to call strcpy to copy the string bytes. This can lead to memory corruption, since strcpy does not use the specified length and will only stop at the first null byte.
Looking at the news opcode, I confirmed that this was fixed by using strncpy now. However, digging further I noted another, albeit less impacting issue.
When loading the definition, TVM first resolves the symbol to its value that stands for a "physical" offset within a section. The most significant byte (MSB) of the symbol specifies which section:
- MSB
0x00(i.e. between0x00000000and0x10000000excluded), we're pointing inside the PRG data section - MSB
0x10(i.e. between0x10000000and0x20000000excluded), we're pointing inside the PRG code section - MSB
0x20(i.e. between0x20000000and0x30000000excluded), we're pointing inside the API data section (stored in the firmware) - MSB
0x30(i.e. between0x30000000and0x40000000excluded), we're pointing inside the API code section (also stored in the firmware)
TVM then uses the lower 6 bytes as the offset within those sections. (There is also MSB 0x40 for native functions but I will get back to them later.)
By API data and code sections, I mean that the firmware embeds a copy of the SDK compiled from MonkeyC. Although it is not a PRG file like an application we would develop, they contain the same data structures. The API code section contains MonkeyC byte code and the API data section contains class and string definitions.
TVM checks that the offset computed from the symbol is within the bounds of the expected section. For instance, if your PRG data section is 0x1000 bytes and you specify the symbol 0xdeadbeef whose value is 0x00aabbcc, it will fail, since 0xaabbcc is beyond the end of PRG data section (0xaabbcc > 0x1000).
However, there is a problem with strings. String definitions specify the length of the data to read and TVM does not check if it goes beyond the end of the section. It is therefore possible to place a string definition at the border of a section, with a large size, and TVM will read data beyond the section's end (up until the next null byte).

In fact, since the sentinel value for string definitions is just 0x01, we can also easily find offsets within the API data and code sections that can be treated as valid string definitions. So we are not restricted in placing our invalid string definitions in our PRG sections, we can also find them in the API sections.
Font Resources
The firmware I analyzed supports two types of fonts: non-Unicode (sentinel value 0xf047) and Unicode (sentinel value 0xf23b). The former no longer is supported when compiling a PRG file but the code for handling them is still present inside the firmware (most likely for retro-compatibility reasons).
The non-Unicode format that is no longer supported is shorter and simpler to describe:
| Index | Size in bytes | Name |
|---|---|---|
| 0x00 | 4 | sentinel value |
| 0x04 | 4 | height |
| 0x08 | 4 | glyph count |
| 0x0c | 4 | min |
| 0x10 | 2 | data size |
| 0x12 | 3 * glyph count | glyph table buffer |
| n | 4 | glyph sentinel |
| n + 4 | 1 * data size | extra data buffer |
When loading a font, the native code incorrectly computes the size of the buffer needed to load the data due to an integer overflow line 7:
e_tvm_error _tvm_app_load_resource(s_tvm_ctx *ctx,int fd,uint app_type,s_tvm_object *resource,s_tvm_object *out)
{
uint size_buffer;
// [...]
file_read_4bytes(fd, &font_glyph_count);
file_read_2bytes(fd, &font_data_size);
size_buffer = (font_data_size & 0xffff) + (int)font_glyph_count * 4 + 0x34;
tvm_mem_alloc(ctx, glyph_table, &glyph_table_data);
// [...]
for (i = 0; i < font_glyph_count; i++) {
glyph = glyph_table_data[i];
file_read_2bytes(fd, glyph);
}
// [...]
}
It is possible to craft a font header that will result in out-of-bound write operations. For instance, selecting the following values:
- Glyph count: 0x4000001A
- Font data size: 0x108
The computed buffer size will be: (0x108 & 0xffff) + 0x4000001A * 4 + 0x34 = 0x1000001a4. Since the registers can only hold 32-bit values, it gets truncated to 0x1000001a4 & 0xffffffff = 0x1a4. The firmware will then try to copy 0x4000001A glyphs to a buffer of 0x1a4 bytes.
Similar issues can be found when parsing Unicode fonts, as well as bitmap resources. However, trying to overwrite large buffers on small, embedded devices can be tricky. I decided to continue reversing the firmware to identify vulnerabilities that may be easier to exploit.
Native Functions
When extracting the API data and code sections from the firmware, I noted that although a lot of functions were implemented in MonkeyC, others were actually implemented natively (as denoted by their symbols starting with 0x40 as mentioned before).
When invoking a method, symbols starting with 0x40 are treated as an index inside a table of callbacks:
// [...]
if ((field_value[0].value & 0xff000000) == 0x40000000) {
// `i * 4` is checked earlier in the function to be within bounds
tvm_native_method = *(code **)(PTR_tvm_native_callback_methods_00179984 + i * 4);
ctx->pc_ptr = (byte *)tvm_native_method;
err = (*tvm_native_method)(ctx, nb_args);
// [...]
In my firmware, I noted 460 native functions! This is quite a large attack surface, since a bug in any of those could potentially allow compromising the OS.
Something to note about symbols starting with 0x40:
- Their 2nd MSB indicates the number of arguments
- The remaining 2 bytes indicates the offset within the table of callbacks
For example, the symbol 0x40050123 points to a native function (MSB is 0x40) that expects 5 parameters (2nd MSB is 0x05) and whose index in the table is 0x123.
Resolving Native Function Symbols
I wanted to resolve the symbols of those native functions to speed up reversing. I located and extracted the API data section based on its 0xc1a55def magic value.
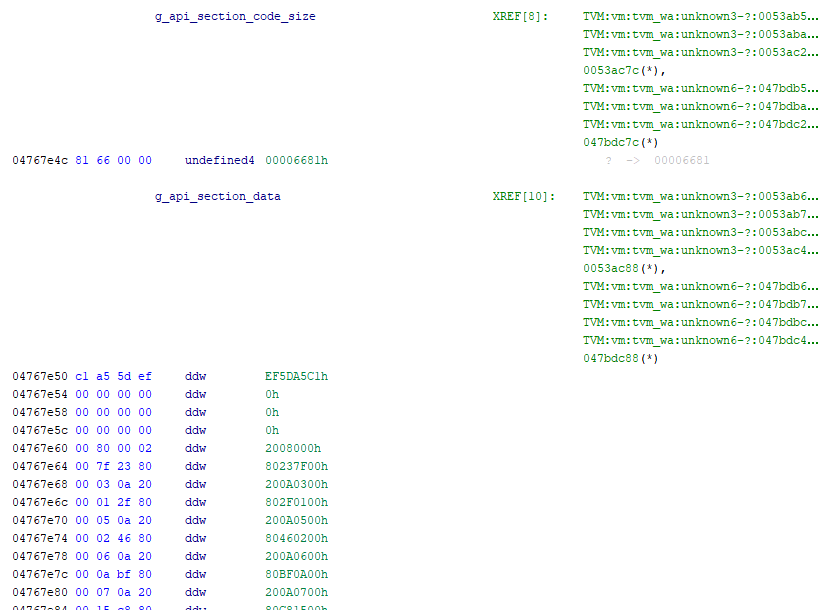
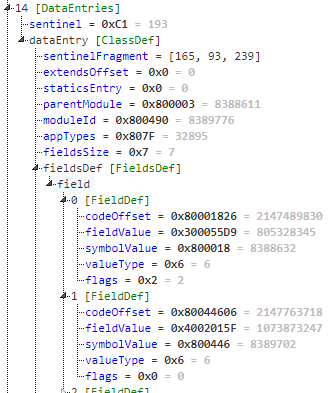
In the screenshot above, we find the following information:
- We are inside the class definition of the module ID
0x800490, which inherits from the module ID0x800003 - The first field definition is a method (type
0x6), whose symbol is0x800018and value is0x300055D9 - The second field definition is also a method (type
0x6), whose symbol is0x800446and value is0x4002015F
For now, let's focus on the second field definition. Since the MSB of its value is 0x40, it is a native function, which takes 2 parameters and is located at offset 0x15F in the callback table.
We can find the debug symbol of 0x800446 in the SDK provided to end-users:
monkeybrains.jar.src$ grep $((16#800446)) ./com/garmin/monkeybrains/api.db getHeartRateHistory 8389702
But there are two getHeartRateHistory according to their documentation. Which one is it? This is where we use the module ID:
monkeybrains.jar.src$ grep $((16#800490)) ./com/garmin/monkeybrains/api.db Toybox_SensorHistory 8389776
Therefore, the native callback at offset 0x15F is Toybox.SensorHistory.getHeartRateHistory. You would have guessed already: the parent module ID 0x800003 is Toybox.
This method appears to only take one parameter (options) but TVM is object-oriented so under the hood, getHeartRateHistory does take two parameters: this and options. (For the curious, the first field definition is the <init> method of the class.)
We can automate this process (Kaitai to Python, plus some additional Python code to parse the debug symbols) for all native functions and rename the functions in Ghidra using their Python scripting API.
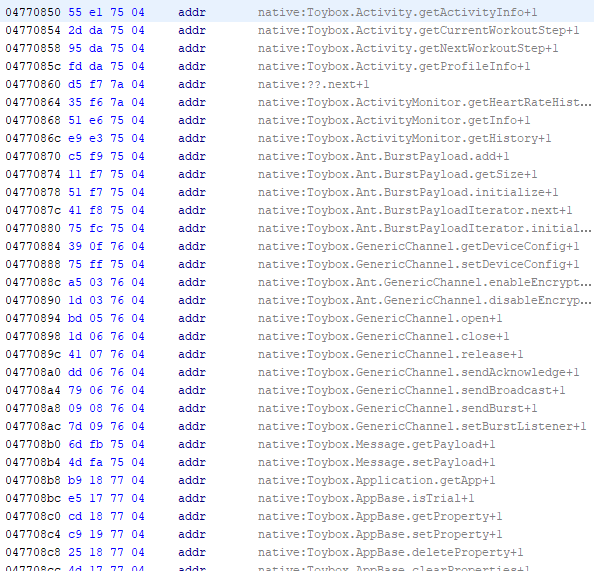
It is now much easier to reverse the native functions, since we can already know their arguments based on the official documentation.
Toybox.Cryptography.Cipher.initialize Buffer Overflows
Looking at the documentation, the Toybox.Cryptography.Cipher.initialize method expects 4 parameters:
-
algorithm, which is an enum to specifyAES128orAES256. -
mode, which is an enum to specifyECBorCBC. -
key, which is aByteArrayof the secret key. -
iv, which is aByteArrayof the initialization vector.
This initialize method is implemented natively in the firmware:
e_tvm_error native:Toybox.Cryptography.Cipher.initialize(s_tvm_ctx *ctx,uint nb_args)
{
// [...]
byte static_key_buffer [36];
ushort key_data_length;
// [...]
// Anvil: Retrieve the key parameter and store it into `key`.
// [...]
// Anvil: Retrieve the underlying byte array data
eVar1 = tvm_object_get_bytearray_data(ctx,(s_tvm_object *)key,&bytearray_data);
psVar2 = (s_tvm_ctx *)(uint)eVar1;
if (psVar2 != (s_tvm_ctx *)0x0) goto LAB_0478fd0c;
// Anvil: And the byte array length
key_data_length = *(ushort *)&bytearray_data->length;
// Anvil: Copy the byte array data to the static buffer
memcpy(static_key_buffer,bytearray_data + 1,(uint)key_data_length);
// [...]
// Anvil: if CIPHER_AES128 then expected size is 16
if (*(int *)(local_78 + 0x18) == 0) {
expected_key_size = 0x10;
}
else {
// Anvil: if CIPHER_AES256, then expected size is 32
if (*(int *)(local_78 + 0x18) == 1) {
expected_key_size = 0x20;
}
// [...]
}
// Anvil: If the key size is unexpected, throw an exception
if (((key_data_length != expected_key_size) && (psVar2 = (s_tvm_ctx *)thunk_FUN_00179a5c(ctx,(uint *)object_InvalidOptionsException,PTR_s_Invalid_length_of_:key_for_reque_047900d0), psVar2 != (s_tvm_ctx *)0x0)) || /* [...] */ ) goto LAB_0478fd1a;
// [...]
In the code snippet above, the native function retrieves the key data and calls memcpy to copy it to the static buffer located on the stack. Once the copy is done, only then does it check the size of the key and throws an error if it has an invalid value.
However, at that point, we already corrupted the stack, including the value for the program counter (PC) register.
The same logic applies to the initialization vector later in the initialize function, although this time the buffer is located on the heap instead of the stack:
// [...]
// Anvil: Retrieves the IV byte array data
eVar1 = tvm_object_get_bytearray_data(ctx,(s_tvm_object *)iv,&bytearray_data);
psVar2 = (s_tvm_ctx *)(uint)eVar1;
if (psVar2 != (s_tvm_ctx *)0x0) goto LAB_0478fc06;
iv_length = bytearray_data->length;
// Anvil: Assigns its length to a structure at offset 0x16
*(short *)(local_78 + 0x16) = (short)iv_length;
// Anvil: Copy the byte array data to the buffer on the heap
memcpy(local_78 + 6,bytearray_data + 1,iv_length & 0xffff);
// [...]
// Anvil: If the IV size is not 16, throw an exception
if (*(short *)(local_78 + 0x16) != 0x10) {
if (psVar2 != (s_tvm_ctx *)0x0) goto LAB_0478fc06;
psVar2 = (s_tvm_ctx *)thunk_FUN_00179a5c(ctx,(uint *)object_InvalidOptionsException,PTR_s_Invalid_length_of_:iv_for_reques_047900dc);
}
// [...]
The following MonkeyC application can trigger the crash when the key parameter is copied:
var keyConvertOptions = {
:fromRepresentation => StringUtil.REPRESENTATION_STRING_HEX,
:toRepresentation => StringUtil.REPRESENTATION_BYTE_ARRAY
};
var keyBytes = StringUtil.convertEncodedString(
"aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaabbbbbbbb",
keyConvertOptions
);
var ivBytes = StringUtil.convertEncodedString(
"aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa",
keyConvertOptions
);
var myCipher = new Crypto.Cipher({
:algorithm => Crypto.CIPHER_AES128,
:mode => Crypto.MODE_ECB,
:key => keyBytes,
:iv => ivBytes
});
Toybox.Ant.BurstPayload Relative Out-of-Bounds Write
Looking at the documentation, the Toybox.Ant.BurstPayload.add method expects just one parameter: message as an array or a byte array. The method adds the message object to an internal buffer. It is implemented natively:
e_tvm_error native:Toybox.Ant.BurstPayload.add(s_tvm_ctx *ctx,uint nb_args)
{
// [...]
// Anvil: Retrieves our current BurstPayload instance object
object = (s_tvm_object *)(ctx->frame_ptr + 5);
field_size = 0;
// Anvil: Retrieves its `size` field
eVar1 = tvm_get_field_size_as_int(ctx,object,&field_size);
uVar2 = (uint)eVar1;
if (uVar2 == 0) {
// Anvil: If the `size` field is >= 0x2000, we abort
if (0x1fff < (int)field_size) {
return OUT_OF_MEMORY_ERROR;
}
// [...]
// Anvil: Retrieves our `message` parameter
eVar1 = tvm_message_copy_payload_data(ctx,ctx->frame_ptr + 10,payload_data);
// [...]
// Anvil: Retrieves our instance's `burstDataBlob` field
eVar1 = tvm_object_get_field_value-?(ctx,object,field_burstDataBlob,&burst_data_blob,1);
// [...]
if ((uVar2 == 0) && (uVar2 = _tvm_object_get_object_data(ctx,burst_data_blob.value,(undefined *)&blob_data), uVar2 == 0)) {
// Anvil: We write our `message` data to the internal buffer.
*(undefined4 *)(blob_data + field_size + 0xc) = payload_data._0_4_;
*(undefined4 *)(blob_data + field_size + 0x10) = payload_data._4_4_;
// [...]
The first thing that stands out is the size field validation. While the function checks the upper bound of its value, it does not check for negative values.
How do we control the size field of the BurstPayload object? MonkeyC supports inheritance, so we can simply inherit from the object and override its value after its constructor was called.
For example, the following code snippet overrides the size field with 0xdeadbeef after calling its parent's initialize method. When calling add, the native function will attempt to write 8 bytes of data, starting at blob_data + 0xdeadbeef + 0xc.
class MyBurstPayload extends Ant.BurstPayload {
function initialize() {
Ant.BurstPayload.initialize();
self.size = 0xdeadbeef;
}
}
// [...]
var burst = new MyBurstPayload();
var data = new[8];
for (var j = 0; j < 8; j++) {
data[j] = 0x44;
}
burst.add(data);
Toybox.Ant.BurstPayload Type Confusion
In addition to the improper size validation, there is another issue in the code. It assumes that burstDataPayload is a certain type of object (looking at the initialize method of BurstPayload, it appears to be a Resource object).
However, using the same technique that we used to redefine the size field, we can change the burstDataPayload field to become another type of object.
For example, the following code changes the burstDataBlob field to an Array object:
class MyBurstPayload extends Ant.BurstPayload {
function initialize() {
Ant.BurstPayload.initialize();
self.size = 0;
// Both objects are INT
self.burstDataBlob = [0, 0];
}
}
// [...]
var burst = new MyBurstPayload();
var data = [
// First object, changing from INT to FLOAT
0x02, 0x42, 0x42, 0x43, 0x43,
// Second object, changing from INT to FLOAT
0x02, 0x45, 0x45,
];
burst.add(data);
When the add function is called, the native function will override the first 8 bytes of the data of the array. These bytes represent the first 2 objects stored (5 bytes of the first object and 3 bytes of the second), which are of type INT. We override them with our own objects of type FLOAT.
The same pattern can be seen in other native functions, where they assume that the object's fields are the same as defined in the SDK. They do not take into consideration the case where those were modified via inheritance.
Now some of the vulnerable native functions require permissions. For the vulnerabilities related to Toybox.Ant.BurstPayload, our CIQ app must add the Toybox.Ant module to its permissions list (along with the Toybox.Background module).
I was interested in understanding how permissions were enforced by the firmware.
Permissions
Module definitions have a flag that specifies if they require permissions to be used. This flag is set for various core modules, such as:
-
Toybox.Antfor Ant-related communication -
Toybox.Positioningto retrieve GPS coordinates -
Toybox.UserProfileto retrieve user-related information such as date of birth, weight, etc. - Complete list here
Then, the PRG file includes the module IDs it needs access to in its permissions section. For instance, if your application needs access to Toybox.UserProfile module, it will include its ID (0x800012) in its permissions section, as shown below:
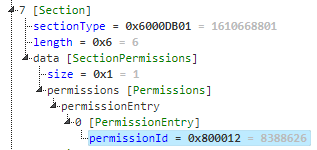
These permissions are then listed on the Connect IQ store for each application. For example, the Spotify CIQ app lists the following permission:
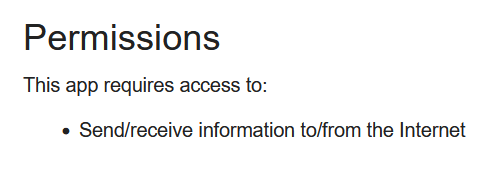
Which corresponds to the Toybox.Communications module.
Checking Permissions
In the firmware, I found the following function that checks the permissions. Its pseudo-code looks as follows:
uint prg_tvm_has_permission(s_tvm_ctx *ctx, int module_id, byte *out_bool) {
// For each module ID in the permissions section
// Is it equal to requested module ID?
// If yes, then we return true as in authorized
// If no, we check the next ID in the section
// No match found, we return false as in unauthorized
}
The first thing that stood out in this function was the following edge case handled early on:
// [...]
bVar1 = module_id == module_Toybox_SensorHistory;
*out_bool = 0
if ((bVar1) && (ctx->version < VERSION_2.3.0)) {
*out_bool = 1;
return 0;
}
// [...]
Tracing the version attribute, I realized that it comes from the version specified in the PRG's head section. We can tamper with the head section to specify a lower version than 2.3.0 and be automatically granted access to the Toybox.SensorHistory module. This module provides access to information such as heart rate, elevation, pressure, stress level, among others.
Up to this point, I was not sure when the prg_tvm_has_permission function was called. Digging further, I noted that it was referenced by the following opcodes:
-
getmto resolve a module -
getvto retrieve an attribute from a module -
putvto update an attribute from a module
The prg_tvm_has_permission receives the module ID of the module that is either being resolved (with getm) or referenced when reading/writing an attribute (with getv/putv).
Unfortunately, we cannot tamper with that module ID since it is parsed directly from the class definitions in the SDK data section, stored in the firmware. Based on testing, attempting to inherit from a privileged module will not work either.
Class and Field Definitions
If you recall the class definition highlighted earlier when resolving symbols, it contains high-level information, such as the parent module ID (if any) and the application types, among others. It also contains a list of field definitions, corresponding to every field defined by the class.
Modules are defined as class definitions in the data section. This is the case for both the modules provided by the SDK and the modules that are created (under the hood) when writing a PRG application.
A field definition can be any MonkeyC type (as listed early on in this blog post) up to type 15 (double) due to how the type is ANDed with 0xf when TVM parses it. This includes integers, strings, other class definitions and methods, among others. It cannot be a primitive module (type 17) or a system pointer (type 18) for instance.
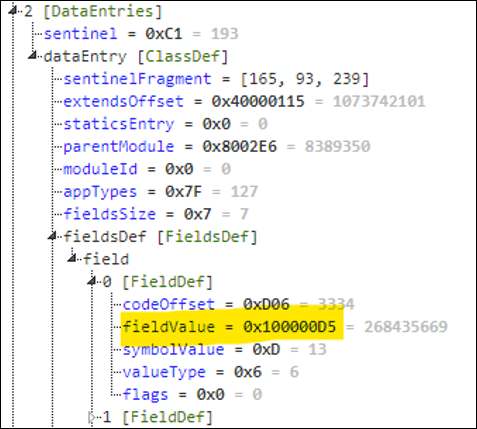
In the class definition shown above, we can see that the first field definition is a method (type 6), whose symbol is 0xD and its value 0x100000D5. If you recall string definitions from earlier, you understand that 0x100000D5 means it is found at offset 0xD5 in the code section of the PRG file.
When calling the method 0xD, TVM will parse the class definition, then its field definitions, until it finds a match for that symbol value. In our case it will find 0x100000D5, translate it to the offset in the correct section (here the PRG code section) and redirect execution there. I am simplifying but that is the gist of it.
Now you may be wondering: what if we updated our field definition value to point inside the SDK section instead? For instance, what if we were to do the following:
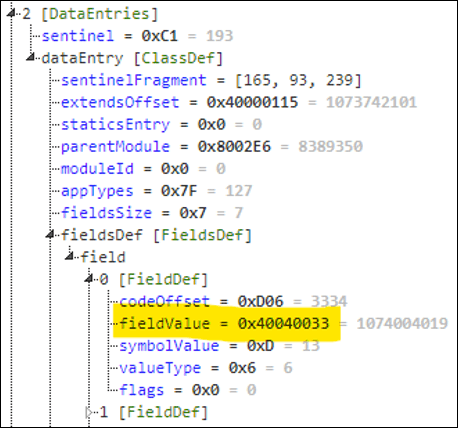
In the updated field definition, we changed 0x100000D5 to 0x40040033. If you recall, this is supposed to represent a native function (0x40) that takes 4 parameters (0x04) and is at offset 0x33 in the callbacks table (the 0x40040033 value is specific to my firmware version). This native function is in fact Toybox.Communications.openWebPage, which is supposed to require permissions since it is inside the privileged Toybox.Communications module.
Now, when TVM checks for permissions, it will end up checking our module ID, meaning checking whether the class definition of our module requires permissions. Since it does not, it will happily let you call the method 0xD, which ends up calling the openWebPage native function.
This can be generalized further: we could embed a full copy of the SDK in our PRG file! We would need to fix various offsets and clear the permission flags. Then, we could use any and all modules, even with an empty permissions section.
This effectively completely bypasses Garmin's permissions check.
Conclusion
In this blog post, I retraced my steps looking at the Garmin Forerunner 245 Music watch. We focused on Garmin applications that can be developed using MonkeyC and run on the device.
We analyzed how the GarminOS TVM runs the apps, focusing on PRG parsing, native functions and permissions. We found bugs during our journey that allow escaping the VM layer and compromise the watch. We also found how we could bypass the Garmin permissions and call any functions, regardless of our app's permissions. I have compiled various scripts and proof-of-concepts to a GitHub repository.
Some of the vulnerabilities such as CVE-2023-23299 were introduced in the first version of the CIQ API (1.0.0), published in 2015. They affect over one hundred Garmin devices, including fitness watches, outdoor handhelds and GPS for bikes.
Future Research Ideas
There are many areas that have not been looked at on Garmin watches (as far as public research shows). We already mentioned the signature validation earlier in this blog post but we also have:
- The Ant and Ant+ stack, used by the watch to communicate with external sensors (e.g. a heart-rate monitor or running pods)
- The Bluetooth Low Energy (BLE) stack, also used with sensors, as well as when the watch communicates with the smartphone (to send data to the Garmin Connect mobile application for instance)
- Some devices also have a Wi-Fi module
- The USB stack, when connecting the device to a computer to copy files
- The filesystem exposed by the device via USB
It would be interesting to know if there are bugs in the protocol stacks, if it is possible to hijack an Ant (or BLE or Wi-Fi) connection for instance and feed malicious data from there. And if the firmware also improperly processes the data received from those protocols.
In addition, the watch can show notifications received on the phone. It could be interesting to understand how those notifications are handled, and if a malicious notification could exploit the watch (e.g. a string format vulnerability when displaying the notification message).
An aspect I did not cover either is per-application storage. Applications have a dedicated storage for saving preferences and other options. It could be interesting to understand how it is implemented, and if it is possible for a malicious application to access and manipulate data stored by another application.
Atredis mentioned trying to patch QEMU to run the watch firmware. I personally did not attempt to perform dynamic analysis, like fuzzing, but this is something that would more than likely help reveal more bugs.
One thing is for sure in my opinion: we only skimmed the surface.
Responsible Disclosure Timeline
- 2022-07-25: Anvil submitted the technical report to Garmin via their web form along with our 90-day disclosure policy.
- 2022-09-11: Garmin acknowledges the vulnerabilities and requests an extension until December 3rd, 2022. We agree.
- 2022-10-14: Anvil submitted a second technical report regarding the permission bypass.
- 2022-11-09: Garmin states that they are on track for December 3rd, 2022 for the initial findings. Garmin acknowledges the permission bypass and requests an extension until February 28th, 2023. We agree.
- 2022-12-01: Garmin states that they identified additional affected products and requests a new extension until March 14th, 2023 for all vulnerabilities.
- 2022-12-06: Anvil agrees on the new deadline and requests the list of affected products.
- 2022-12-13: Garmin provides the list of affected devices, identified by Connect IQ API version.
- 2023-01-09: Anvil requests CVE IDs.
- 2023-01-26: MITRE assigns CVE IDs (CVE-2023-23301, CVE-2023-23298, CVE-2023-23304, CVE-2023-23305, CVE-2023-23302, CVE-2023-23303, CVE-2023-23306, CVE-2023-23300, CVE-2023-23299).
- 2023-01-27: Anvil shares CVE IDs with Garmin and asks if they are planning to publish a security advisory.
- 2023-02-01: Garmin states that they are not planning on publishing an advisory listing the CVEs.
- 2023-03-14: Anvil asks Garmin if they have released the new firmware images for the affected devices.
- 2023-03-16: Garmin states that the majority of the updates have been released. They specify that three devices have been delayed and that they are targeting March 22nd, 2023